

 如果结果不匹配,请
如果结果不匹配,请 
 更多“儿茶酚胺随机尿样本描述正确的是()”相关的问题
更多“儿茶酚胺随机尿样本描述正确的是()”相关的问题
第1题
关于质性研究的特点,以下哪项是正确的描述?()
A.常使用超过200例的大样本调查
B.常使用随机抽样的方法纳入受试对象
C.随机分配受试对象到试验组和对照组
D.深入访谈法常常是收集资料的主要方法
第2题
以下关于随机森林算法的描述中错误的是()。
A.可以处理高维度的属性,并且不用做特征选择
B.随机森林的预测能力不受多重共线性影响
C.也擅长处理小数据集和低维数据集的分类问题
D.能应对正负样本不平衡问题
第3题
下面哪一句话对概率近似正确(probably approximately correct, PAC)的描述是不正确的()?
A.强可学习和弱可学习是等价的,即如果已经发现了“弱学习算法”,可将其提升(boosting)为“强学习算法”
B.强可学习模型指学习模型仅能完成若干部分样本识别与分类,其精度略高于随机猜测
C.强可学习模型指学习模型能够以较高精度对绝大多数样本完成识别分类任务
D.在概率近似正确背景下,有“强可学习模型”和“弱可学习模型”
第4题
对于随机过程而言,下列说法正确的是:()。
A.随机过程是随时间变化的随机变量
B.随机过程的每一条样本函数都是一个确定的时间函数
C.随机过程的每一条样本函数都是随机变化的
D.随机过程是样本函数的集合
第7题
设有一批产品,为估计其废品率p,随机取一样本X1,X2,...,Xn,其中证明:是p的一致无偏
设有一批产品,为估计其废品率p,随机取一样本X1,X2,...,Xn,其中

证明: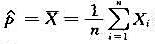 是p的一致无偏估计量(即同时满足一致性与无偏性的估计量)。
是p的一致无偏估计量(即同时满足一致性与无偏性的估计量)。
第8题
若随机过程X(t)的样本函数可用傅氏级数表示为 其中t0是在一个周期内均匀分布的随机变量,an,bn
若随机过程X(t)的样本函数可用傅氏级数表示为
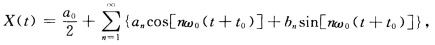 其中t0是在一个周期内均匀分布的随机变量,an,bn是常数,试求出X(t)的功率谱密度.
其中t0是在一个周期内均匀分布的随机变量,an,bn是常数,试求出X(t)的功率谱密度.
第9题
在样本管理中,下列说法正确的是()。
A.按照脚本提取的结果,全量传递,不得增删
B.所有的样本数据原则上通过系统手段传递
C.在开展CATI、短信和邮件评测中,在既定的条件范围内,样本必须随机抽取
D.场景式实时评测面向符合触发条件的重点用户
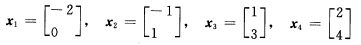 求其K—L变换。
求其K—L变换。















