 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在以标准正态分布的分位数,为被解释变量估计概率单位模型时,采用的模型为 Ii=β0+β1Xi+μi 随机干扰项μi有
在以标准正态分布的分位数,为被解释变量估计概率单位模型时,采用的模型为
Ii=β0+β1Xi+μi
随机干扰项μi有如下的方差:

其中fi是对应于F-1(Pi)的标准正态分布的概率密度函数。根据例5与例6的相关数据资料,计算随机干扰项的方差,并求适当的权数以对上述模型进行WLS估计。
查看答案

 如果结果不匹配,请 联系老师 获取答案
如果结果不匹配,请 联系老师 获取答案

 更多“在以标准正态分布的分位数,为被解释变量估计概率单位模型时,采…”相关的问题
更多“在以标准正态分布的分位数,为被解释变量估计概率单位模型时,采…”相关的问题
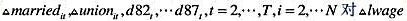 作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
作回归分析,确保包括一个常数项和一个从1982年到1987年的时间虚拟变量。算出Δmarried和Δunion的系数和标准误。
















